DuckDB is an in-process SQL OLAP database management system designed for efficient analytical queries. It's optimized for fast read-heavy workloads and is ideal for data science applications, especially when working with Pandas and large datasets.
Basic Usage of DuckDB
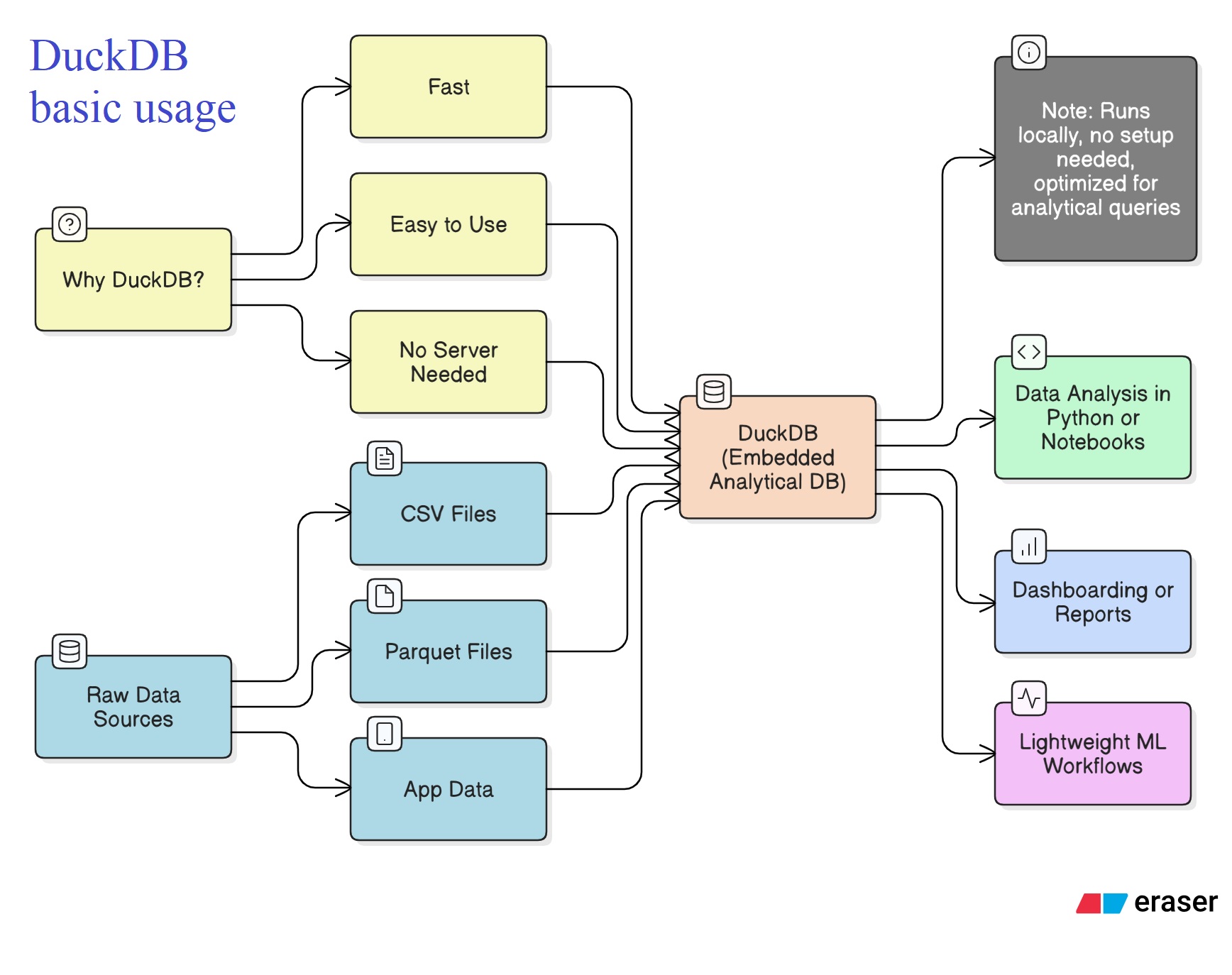
Key Features
- SQL support for analytical queries
- Seamless integration with Pandas DataFrames
- No server required - runs embedded in Python
- High performance on columnar storage
- Export results to Arrow, Parquet, and Pandas
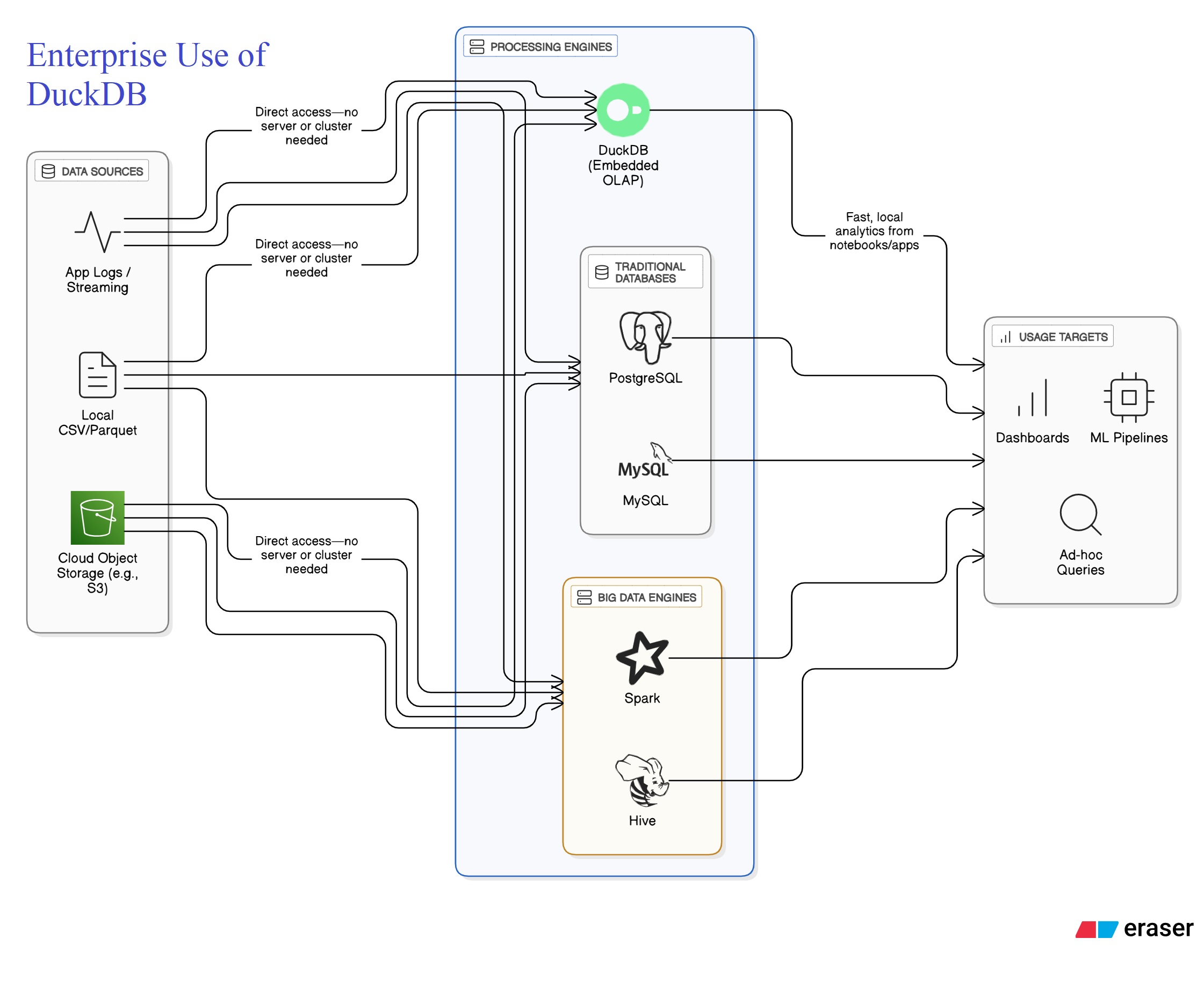
DuckDB in Enterprise Use
duckdb package installation
duckdb website: https://duckdb.org/ duckdb documentation: https://duckdb.org/docs/ duckdb windows package GitHub: installer file
Installation Steps
- Download the DuckDB CLI for your platform from the official website.
- Unzip the downloaded file to a directory of your choice.
- Add the directory to your system's PATH environment variable.
- Verify installation by running `duckdb` in your terminal or command prompt.
- For Python integration, install the DuckDB Python module using pip.
Do we need Installer package and pip module both?
No, you do not need both the installer package and the pip module. The installer package is for using DuckDB as a standalone command-line tool, while the pip module allows you to use DuckDB directly within Python scripts. Choose one based on your use case.
duckdb python module Installation
pip install duckdb10 Examples
import duckdb
import pandas as pd
# Example 1: Run a SQL query on a Pandas DataFrame
df = pd.DataFrame({"id": [1, 2, 3], "value": [10, 20, 30]})
result = duckdb.query("SELECT * FROM df WHERE value > 15").df()
print(result)
# Example 2: Simple SELECT query
print(duckdb.query("SELECT 42 AS answer").fetchall())
# Example 3: Create a DuckDB table
duckdb.query("CREATE TABLE items (name VARCHAR, price INTEGER)")
# Example 4: Insert values
duckdb.query("INSERT INTO items VALUES ('Pen', 10), ('Book', 30)")
# Example 5: Select from table
print(duckdb.query("SELECT * FROM items").fetchdf())
# Example 6: Aggregate functions
print(duckdb.query("SELECT AVG(price) FROM items").fetchone())
# Example 7: Join operations
users = pd.DataFrame({"id": [1, 2], "name": ["Alice", "Bob"]})
scores = pd.DataFrame({"id": [1, 2], "score": [90, 85]})
query = "SELECT u.name, s.score FROM users u JOIN scores s ON u.id = s.id"
print(duckdb.query(query).df())
# Example 8: Working with Parquet
# duckdb.query("CREATE TABLE parquet_table AS SELECT * FROM 'data.parquet'")
# Example 9: Export to Pandas
data = duckdb.query("SELECT * FROM items").df()
print(data)
# Example 10: Using SQL functions
print(duckdb.query("SELECT LENGTH('DuckDB')").fetchone())